CS 385 : Sliding Window Face Detector Using HoG

Animation of Sliding Window
Introduction:
In face detection there are many problems that occur when it comes to finding faces in a picture. When thinking about face detection we had to start with the simplest of thoughts; simply what makes a face a face? Next we thought about what makes a face a face, we came up with a key list: eyes, nose, mouth, ears, eyebrows, expressions, and facial hair. To implement a face detector we had to train an algorithm to be able to find the faces by teaching it simply what a face should look like, in other words teach it what a face is. Once we overcame teaching the algorithm what a face is, we then ran into the problem of, not all faces look the same. When teaching the algorithm to detect faces, we had to take into account that not all faces are front views; we thought about if a face is in an non-frontal view, i.e.downward face, side profile, partially covered, and also deformed faces. Our ultimate goal was to be able to have our face detector find every face in an image accurately, no matter size or angle of the face. Once we reached the end goal of our project we had successfully created a face detector that could correctly detect many different faces in an image.
What Is It Good For.... Absolutely Something!
Our purpose for facial detection is much more than it being fascinating to train a computer to essentially have eyes, but to be able to expand the capabilities of a computer's ability to help. With facial detection, you are able to log into your computer with just a look at your computer. Also being able to identify a person with a trusted algorithm. For example, facial detection is a useful tool for facial recognition in say a police database. The possibility of a computer to be able to detect a face in surveillance footage would make jobs a bit easier. Next the possibility of the image being able to be matched to a database of mugshots to identify a person would be a lot easier than to look at every image individually.
Start Detecting
In the beginning stages we were able to detect faces right off the back, once our code was implemented, but we had a problem with accuracy. First we had ran into problems with getting the positive features from the training set database.Dividing the 36x36 images into 6x6 sub-patches caused some minor issues, as our math was wrong causing us to go beyond the image borders. Once we were able to get passed that, we were able to go on to compute the histogram of gradients (HoG) orientations. Next we went on to obtain the positive and negative features. In this process we went on to train our SVM classifier to be able to determine what a correct face should be similar to and to determine a positive feature. For negative features we went on to do the same thing but train it with images that don't have faces.

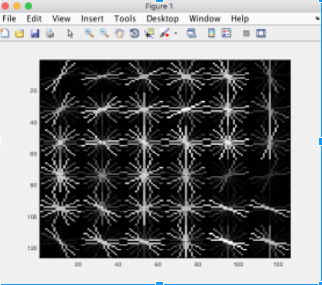
(Positives)
(Negatives)
Training our SVM classifier with the HoG of negative and positive features we were able to get a average HoG of all the faces. In the process of training our SVM classifier we had to create a vector of negative and positive features and create a double vector with -1's and 1's, simulating positive and negative, to label our training points.
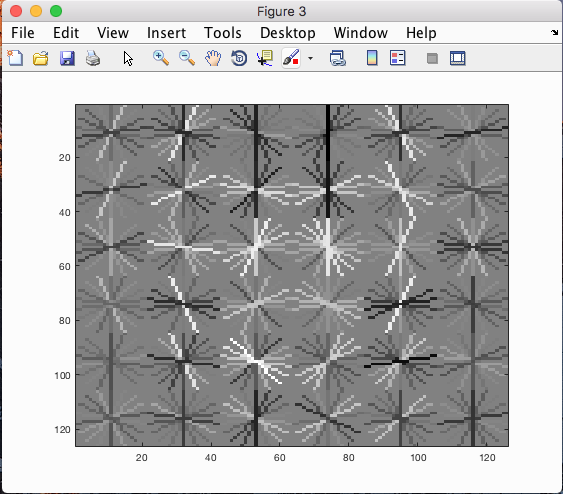
(Average HoG)
After training our SVM classifier were were able to get some good numbers. The HoG for all the images is what we will be comparing out subpatches of our photo to. The sliding window will move along the photo and create a HoG of the subsection and compare that to the overall HoG.
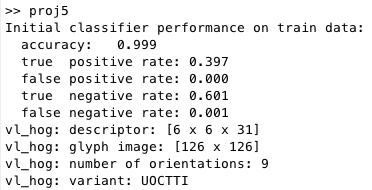
(accuracy of SVM training data)
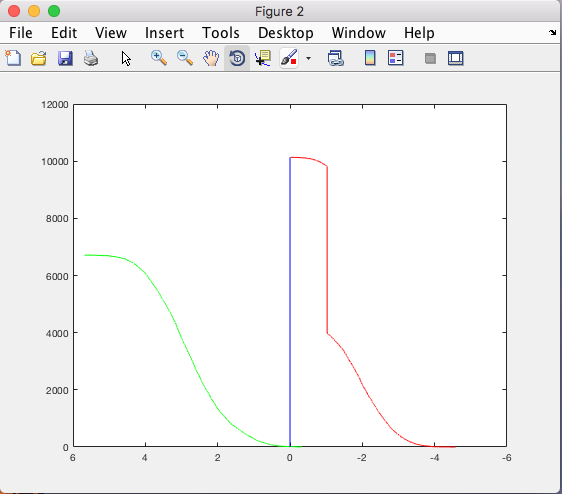
The above graph shows the rate of positive (green) and rate of negatives (red) that we would find based on how we scaled our image. Single scale we never scaled our image to account for different size faces.

The above graph shows the rate of positive (green) and rate of negatives (red) that we would find based on how we scaled our image. Multi-scale we scaled our image to account for different size faces. As you can see our rate of negatives became more constant towards 0 telling us that the more the red hits the 0 (blue) the less negatives we find as the green constantly moves away from 0, and the more accurate our facial detector becomes. Therefore, showing that the more images that the SVM is trained with different scales it becomes more accurate.
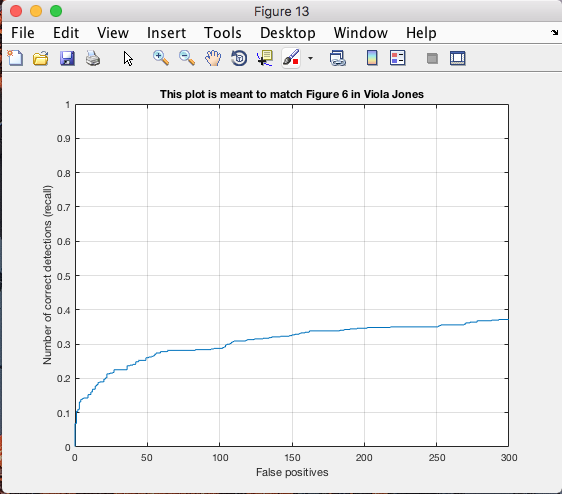
Finally we applied the sliding window to the images and rescaled the images. First we used the single scale detector to be able to compare with the multi-scaled detector. By comparing the two we were able to see that our precision was highly altered, as it increased.
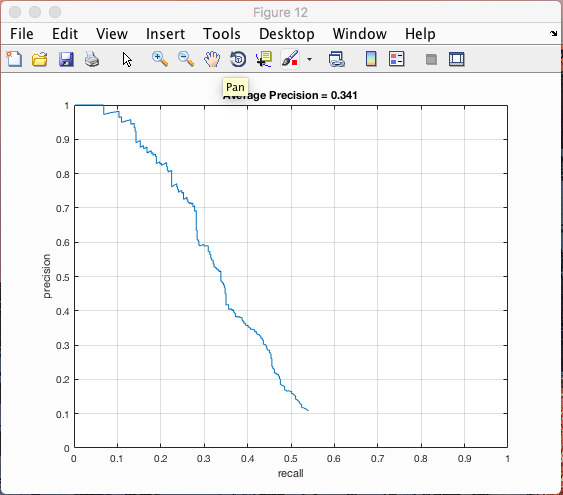
(Single Scale Precision)

(Multi-Scale Precision)
By rescaling we are able to find different size faces, but we ran into a problem with resizing those found faces onto a normal scaled image. To use multiple scales, we would resize the photo approximately 10% and slide our window along the bounds of the image. Each time we reduce the pixels, resulting in the window checking a larger area for a face, essentially finding different size faces. With the scaling of images we ran into a problem of scaling the found faces on the normal scaled image after all faces were found. To avoid this problem we had to be double check our math and multiply our detected faces for that scale size by the scale size for it to be able to become normal.
Alternate Oriented Faces
Lastly we decided to train our code to be able to not only detect singular posed faces, but alternately oriented faces. After finding the singular posed faces we found it to be easier to simply add another set of databases to train our SVM classifier to detect different angled faces. We created an HoG average for different angled faces to repeat the process. Once trained we were able to detect more faces within the images, also including finding some faces we couldn't find at all.
Some Final Results

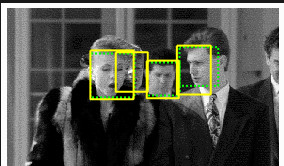

|


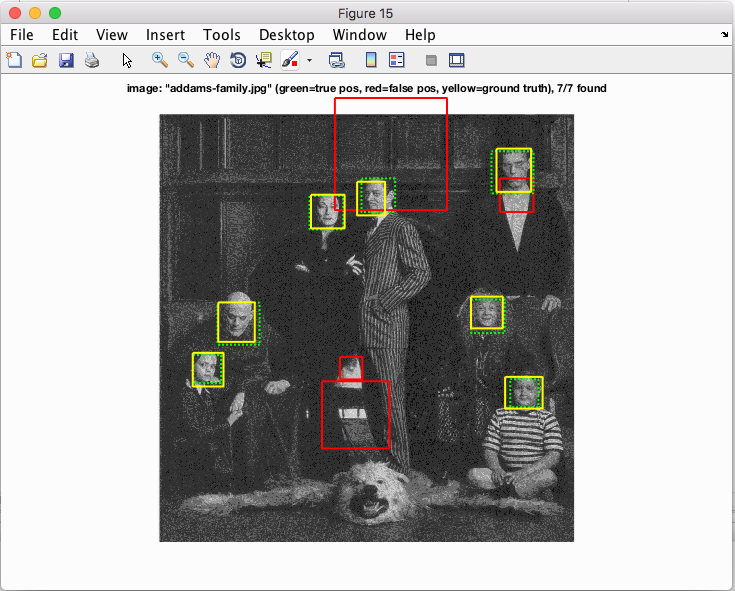
|
Final Thoughts and Conclusion
In conclusion we were quite successful in building a sliding window facial detector. With a cell size of 3, we achieved a precision rate of over 0.9, which is very good. When implementing the orientation detector, however, we had trouble finding a large enough training dataset for our classifier training. That being said, we were able to achieve precision rates equal to if not slightly better than our original single-orientation facial detector.
At first we tried to build a single classifier for all orientations, but quickly realized that that wasn't a very effective way of doing it. Because we tried this, we wasted a good amount of time, and weren't able to spend as much time tweaking our detector as much as we could have. If we had to do it all over from scratch, we would definitely go straight to multiple classifiers, and try to find more data for our training dataset.