CS 385 : TextonBoost - Parking Lots

Example of a right floating element.
Introduction
TextonBoost is an approach to multi-class classification that attempts to segment photographs into various classes. This model seeks to use texture-layout filters, or features based on textons.
Classification and feature selection is achieved using boosting to give an efficent classifier which can be applied to a large number of classes.
- The aim of our project was to apply TextonBoost to determine where there are occupied and vacant spaces in a parking lot.
- Initially, the codebase worked on 24 classes, but we had to sift through the codebase and instead add two new categories, occupied and unoccupied.
- Our team leveraged two datasets to train our model for this purpose. The PKLot and UIUC datasets, each housing many images that show cars and parking spaces in different poses and/or lighting conditions.
- When using the UIUC dataset, the images had varying results, but when using the PKLot dataset with default parameters, We were able to determine where some occupied spots were with relatively little difficulty.
Approach/Algorithm
A simplified explanation of TextonBoost is:
Learn a boosting classifier based on relative texture locations for each class. The classification is then refined by combining various weak classifiers and then combining them to construct a classifier that has a higher accuracy than any of the individual classifiers would produce on their own.
-
Given an image and for each pixel:
- Texture-Layout features are calculated
- A boosting classifier gives the probability of the pixel belonging to each class
- The model combines the boosting output with shape, location, color and edge information
- Pixel receives final label.
- Image receives final label.
Extensions to existing TextonBoost framework
- The original algorithm used a filter bank with 3 Gaussians, 4 Laplacian of Gaussians and 4 first order derivatives of Gaussians. In addition to these filters, we augmented the filter bank to also use dense SIFT. Dense SIFT differs from regular SIFT in that dense SIFT assumes every pixel is a point of interest. We also modified the approach of the framework to only care about 3 classes, void, car, unoccupied.
- When working with the data set UIUC, the algorithm needed to be altered to account for gray scale images. To process a gray scale image they first need to converted to a 3 dimensional image matrix to simulate an RGB image matrix. Than the code needs to be altered, so that Hue and Saturation are not used when textonizing images. Removing Hue and Saturation results in decreasing the number of features per pixel from 17 to 11.
- The pixel feature descriptors that were aggregated from applying the various filters are clustered using k-means. We varied the value of k for k-means clustering to determine the optimal number of clusters for our model.
- Additionally, to balance the trade-off between too much noise in the image from image textonization, keeping enough information for accuracy and speed of training, the image in testing and the training set are sampled with a filter. We also varied the size of the filter used in the various filter banks that already existed in the framework.
- When using the UIUC data set, the number of features decreases from 17 to 11. So the parameter numFeatures in the file imgTextonization.m must be changed to 11. This parameter change will account for less features used, and result in a smaller code book generated.
Results
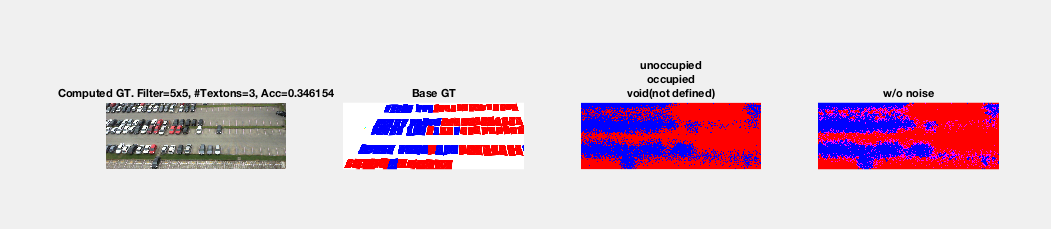
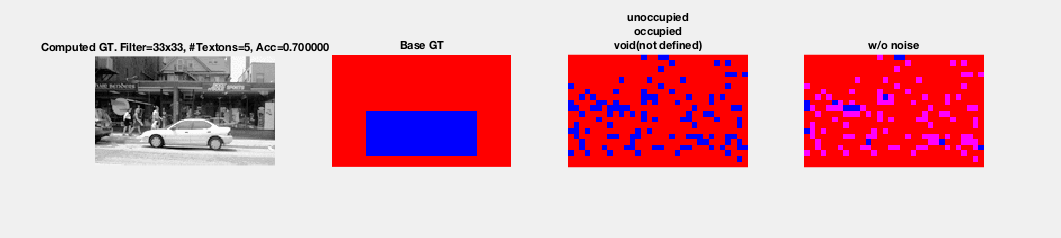
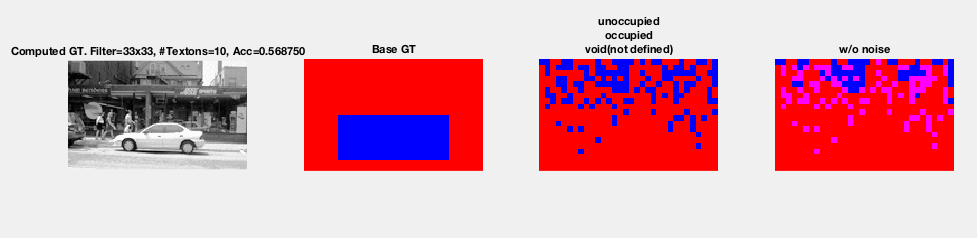
- Problems with Input Images
- All of the Input Images in the PKLot data set span a large parking lot. Since the input images are not taken from the zenith of the center of the parking lot, the resulting images will result in objects of varying size because parking spaces at one of end of the lot can be much smaller than spaces at another end of the lot. The objects (e.g. cars, unoccupied spots, etc.) in the foreground will be much larger and more defined than the objects in the background. To account for this problem we cropped the original images to capture a small location, where the object's have less varying sizes.
- Problems with Ground Truth Images
- In a perfect world the Ground Truth Images should have every pixel colored as either void, car, or unoccupied. Unfortunately because the PKLot metadata associated with the images did not describe complex polygons that exactly match the contours of a car in a parking spot. Instead the PKLot data set simply provided rectangles that approximately cover a parking spot. This metadata causes issues because there is extraneous information used to describe a car. This means that if, for example, there is a crowded parking lot in the training set and we have a given spot as empty, the model will train on ground truth images that have shadows from adjacent cars and think that these shadows characterize an empty spot.
- In addition, the Ground Truth metadata provided by PKLot also has a small subset of polygons that would overlap with each other. This will cause issues in the training phase because pixels associated with a given class can be classified inaccurately. For example, consider an empty parking spot with two cars on each side of it. If the Ground Truth image for an occupied spot covers a portion of the two cars, unwanted textures will be introduced to describe the unoccupied spot's class category.
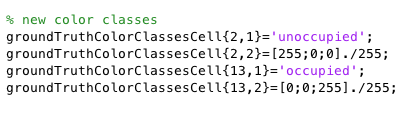
Our new color classes
Output Images

|

|

|

|

|
|
|
|
Some figures
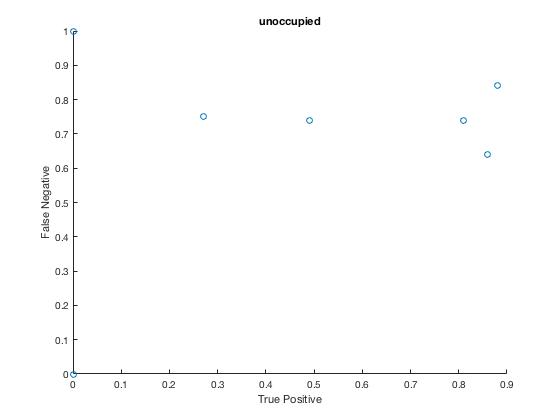

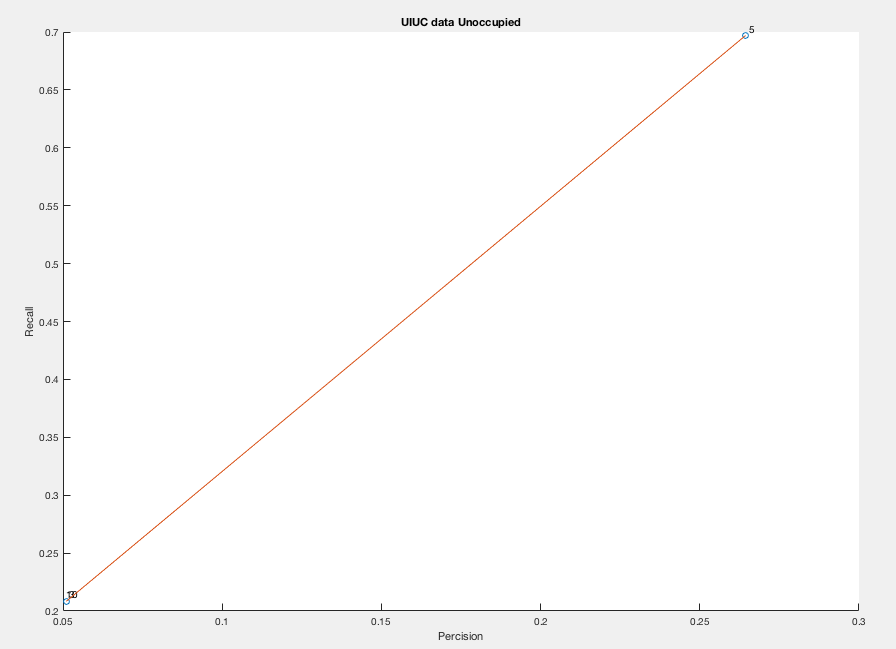
Legend:
Point 10: Number of Clusters = 10.
Point 3: Number of Clusters = 3.
Point 5: Number of Clusters = 5.
Point 20: Number of Clusters = 20.
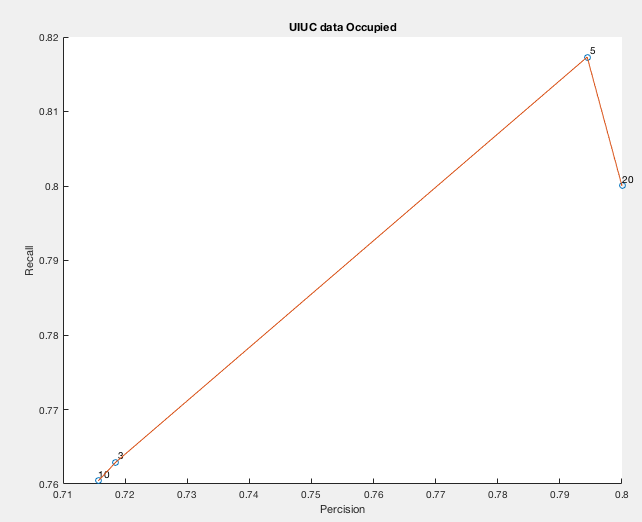
Legend:
Point 10: Number of Clusters = 10.
Point 3: Number of Clusters = 3.
Point 5: Number of Clusters = 5.
Point 20: Number of Clusters = 20.
Discussion and Conclusions
- The codebase seemed to use k-means clustering at an odd time. We posited that k-means clustering should be used on all of the data at one time. Instead, the codebase seemed to use k-means clustering on each image independent of the other images.
- Understanding all the various pieces that made the code run, from textonization to training of the model, all involved multiple files and assumed the user of the framework had an intimate understanding of the approach.
- Introducing dense SIFT was a challenge because the filter-bank used initially on each pixel worked on all pixels. Unfortunately, dense SIFT cannot operate on pixels too close to a boundary. Our team overcame this challenge by adjusting the size that the filter-bank dealt with to the same dimensions as the dense-SIFT portion of the image.
- Trying to find a good data set was difficult. While testing the functionality of our code we came across many problems caused by input images. With the PKLot data set one of the most obvious problems we noticed was that objects' size varied based on location within the image. In order to get input images with objects of relatively similar size we cropped a small area out of the original images in the PKLot data set. Cropping the original images also had the benefit of speeding up the code because there would be less pixels to train on.
- We also tried cropping individual objects of interest out of the PKLot data set images. Cropping individual images provided an additional data set, where we could train on either cars or empty parking spots. The difference between these segmented images and the original images with an entire parking lot in view is that the original images included other objects like grass, roads, & people that could interfere with training. The result of these segmented images provided input images with less noise.
References
MSRC framework from MicrosoftResearch paper from Microsoft
TextonBoost framework in Matlab documentation